CPU 实现
- Y86-64 指令集
- 通用寄存器与 x86-64 的基本相同,除了没有
%r16。 - 标志位包括
ZF、SF、OF。 - 多字节数据采用小端序存储。
- 可用指令
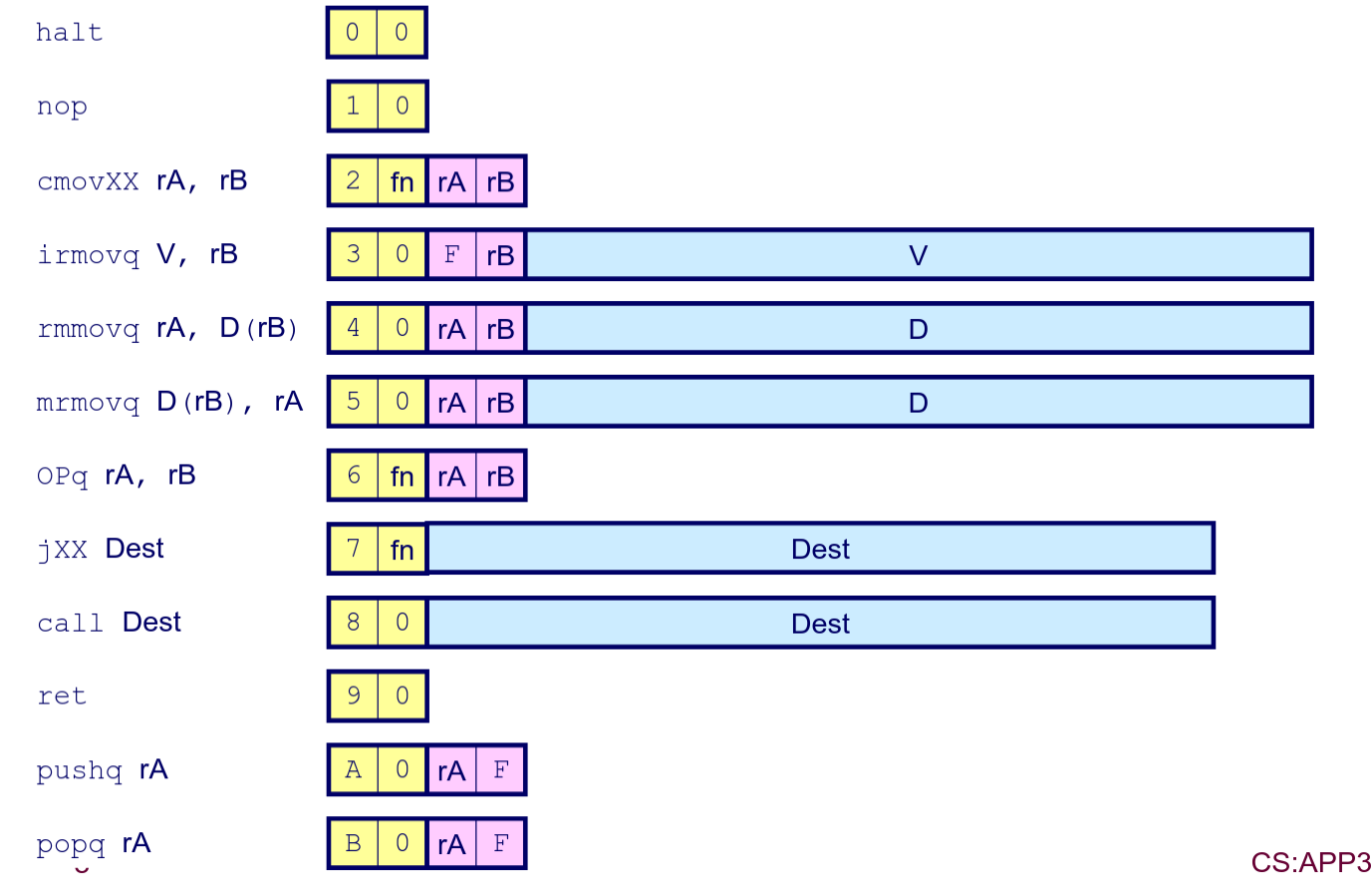
cmovXX和jXX中的XX都是指各种偏序关系。
- 通用寄存器与 x86-64 的基本相同,除了没有
- HCL
- 数据类型
- 布尔型:
bool a。 - 整数型:
int a,不指定长度。
- 布尔型:
- 表达式
- 逻辑运算:
a && b、a || b、!a。 - 关系运算:
a < b、a > b、a <= b、a >= b、a == b、a != b。 - 集合运算:
a in { b, c, d }。 - 多路选择:
[ a: A; b: B ],按照顺序判断:前的条件是否成立,成立时:后的表达式就是整个表达式的值。
- 逻辑运算:
- 数据类型
- 顺序处理器
- 执行流程
- 取指:从内存读取指令。
- 译码:读取寄存器。
- 执行:计算值或地址。
- 访存:读取或写入内存。
- 写回:写入寄存器。
- Y86-64 实现
OPq rA, rB- 取指:
icode:ifun <- M[PC], rA:rB <- M[PC + 1], valP <- PC + 2。 - 译码:
valA <- R[rA], valB <- R[rB]。 - 执行:
valE <- valA OP valB, set CC。 - 访存:无。
- 写回:
R[rB] <- valE。 - 更新 PC:
PC <- valP。
- 取指:
rmmovq rA, D(rB)- 取指:
icode:_ <- M[PC], rA:rB <- M[PC + 1], valC <- M[PC + 2..PC + 10], valP <- PC + 10。 - 译码:
valA <- R[rA], valB <- R[rB]。 - 执行:
valE <- valC + valB,这里地址相加可以直接使用 ALU。 - 访存:
M[valE..valE + 8] <- valA。 - 写回:无。
- 更新 PC:
PC <- valP。
- 取指:
popq rA- 取指:
icode:_ <- M[PC], rA:_ <- M[PC + 1], valP <- PC + 2。 - 译码:
valA <- R[%rsp], valB <- R[%rsp]。 - 执行:
valE <- valB + 8。 - 访存:无。
- 写回:
R[rA] <- valA, R[%rsp] <- valE。 - 更新 PC:
PC <- valP。
- 取指:
cmovXX rA, rB- 取指:
icode:ifun <- M[PC], rA:rB <- M[PC + 1], valP <- PC + 2。 - 译码:
valA <- R[rA], valB <- 0。 - 执行:
valE <- valA + valB, if !cmov_cond(CC, ifun) { rB <- 0xF }。- 使用
valB为0并相加应该是为了简化逻辑,不需要考虑不经过 ALU 的情况。 0xF不存在一个对应的寄存器,也就是不修改任何寄存器。
- 使用
- 访存:无。
- 写回:
R[rB] <- valE。 - 更新 PC:
PC <- valP。
- 取指:
jXX Dest- 取指:
icode:ifun <- M[PC], valC <- M[PC + 1..PC + 9], valP <- PC + 9。 - 译码:无。
- 执行:
Cnd <- jump_cond(CC, ifun)。 - 访存:无。
- 写回:无。
- 更新 PC:
PC <- Cnd ? valC : valP。
- 取指:
call Dest- 取指:
icode:_ <- M[PC], valC <- M[PC + 1..PC + 9], valP <- PC + 9。 - 译码:
valA <- R[%rsp]。 - 执行:
valE <- valA - 8。 - 访存:
M[valE..valE + 8] <- valP。 - 写回:
R[%rsp] <- valE。 - 更新 PC:
PC <- valC。
- 取指:
ret- 取指:
icode:_ <- M[PC], valP <- PC + 1。 - 译码:
valA <- R[%rsp], valB <- R[%rsp]。 - 执行:
valE <- valA + 8。 - 访存:
valM <- M[valB..valB + 8]。 - 写回:
R[%rsp] <- valE。 - 更新 PC:
PC <- valM。
- 取指:
- 执行流程
- 流水线处理器
- 基本思想
- 在基本的 5 个阶段前插入寄存器,每个周期执行一个阶段。
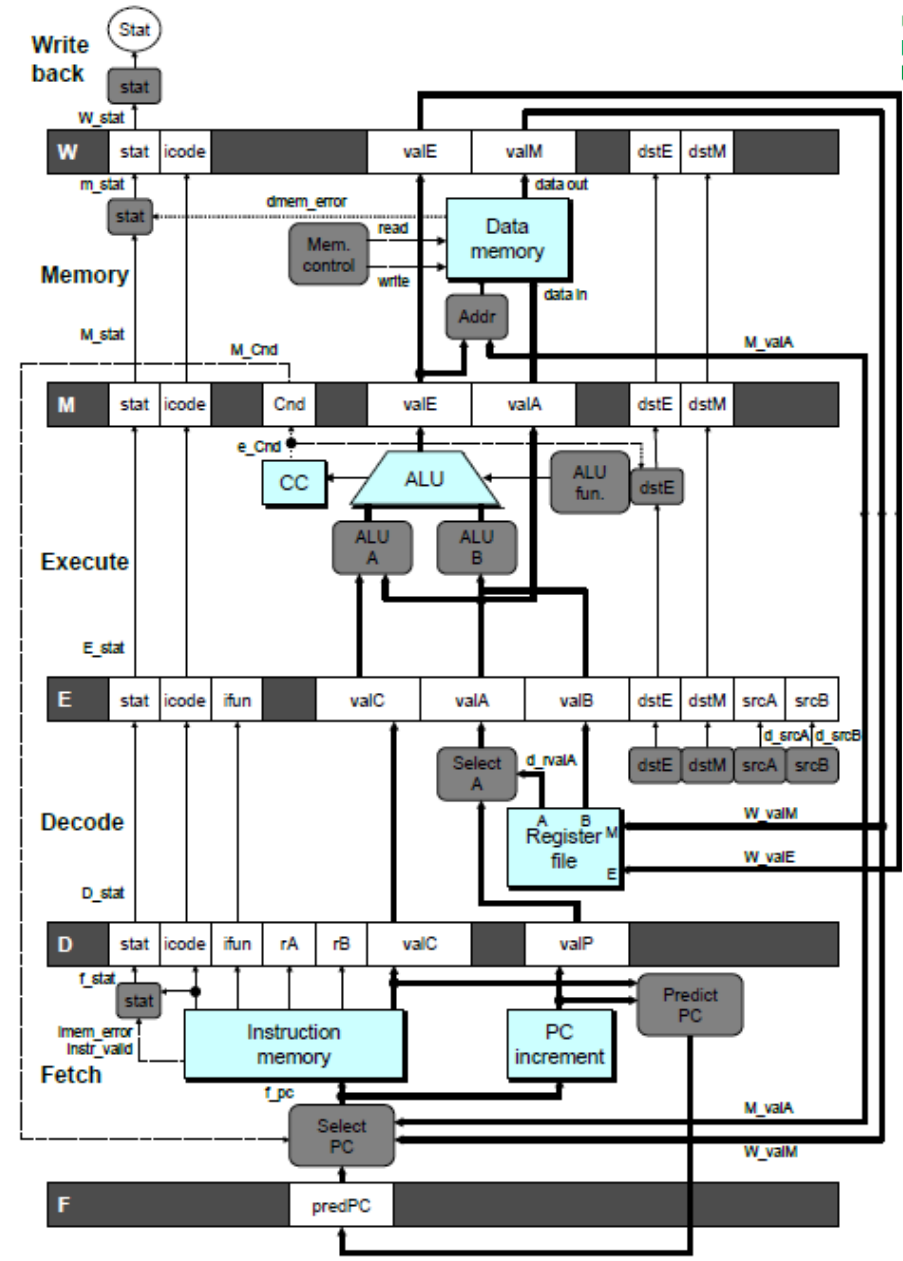
- 分支预测策略:
- 不跳转的指令:PC 的下一个值。
call、无条件跳转:目标地址。- 条件跳转:只选择目标地址。
ret:不预测。
- 基本实现存在的问题
- 数据冒险:
- 数据依赖:前一个指令还没有写回寄存器,后一个指令已经取出值。
- 控制冒险:
- 分支预测错误:预测错分支后已经开始执行了错误的指令。
ret指令:只有访存后才可以获得返回地址,但是已经开始执行ret后的指令。
- 数据冒险:
- 解决数据依赖问题
- 数据依赖都发生在译码和后续阶段之间:
- 译码需要读取
srcA、srcB两个寄存器。 - 执行、访存、写回会准备写入
dstE、dstM两个源寄存器。
- 译码需要读取
- 暂停解决:
- 当
srcA或srcB为0x15时,此寄存器必定不会依赖更早执行的指令。 - 否则当
srcA、srcB之一和e_dstE、E_dstE、m_dstM、M_dstE、M_dstM之一相等时,产生数据依赖。 - 通过组合逻辑电路实现检查,暂停取指、译码阶段的运行,直到值被写入寄存器。
- 缺点:效率较低,无论如何都要等到依赖的指令到达写回阶段。
- 当
- 数据转发解决:
- 依赖的数据不一定要等到写入寄存器后才去读取,这些值在更早的阶段就已计算好。
- 通过数据旁路把结果传回译码阶段,实现电路根据是否依赖选择从寄存器或旁路读取。
valA需要从寄存器读取时,若不存在依赖,d_valA从寄存器取,否则取依赖的旁路的值。valB同理。- 源寄存器与多个目的寄存器相同时,选择所处阶段最早的,即最新指令的结果。
- 装载/使用冒险:数据转发引入的问题。
irmovq和popq修改寄存器的值只有访存后才知道,而数据转发需要在执行阶段就获取结果。- 当依赖还在执行阶段的这两个指令
dstM时,即依赖E_dstM时,产生装载/使用冒险。 - 检测条件为
E_icode in { IMRMOVQ, IPOPQ } && E_dstM in { srcA, src B }。 E_dstM在数据旁路中并没有对应的数据,必须暂停取指、译码一个周期。
- 数据依赖都发生在译码和后续阶段之间:
- 解决分支预测问题
- 因为预测策略中一直选择跳转到目标,所以预测错误是在执行阶段得到
!e_Cnd。 - 检测条件为
E_icode == IJXX && !e_Cnd。 - 检测到预测错误后,把取指、译码阶段转换为气泡。
- 因为预测策略中一直选择跳转到目标,所以预测错误是在执行阶段得到
- 解决返回
- 在
ret到达访存阶段前,返回地址一直是未知的,前面阶段的指令都不应该执行。 - 检测条件为
IRET in { D_icode, E_icode, M_icode }。 - 检测到返回时,暂停取指,把译码转换为气泡。
- 在
- 基本思想